Many vision tasks such as scene alignment, image fusion, and image editing and enhancement often require finding dense visual correspondence, which is also known as Nearest Neighbor Fields (NNF) estimation. Specifically, the goal is to estimate a pair of corresponding points between two (or more) consecutive images, taken from different viewpoints or at different time instant. Establishing reliable correspondences is generally known as an ill-posed problem due to various challenges such as varying lighting condition, noise, and lack of good patch/image representation. We have proposed several novel methods to significantly improve the performance of visual correspondence. Based on the expertise on visual correspondence, I presented two half-day tutorials, entitled “Visual Correspondences: Taxonomy, Modern Approaches and Ubiquitous Applications” in IEEE Int. Conf. on Multimedia and Expo (ICME) 2015 and “Discontinuities-Preserving Image and Motion Coherence: Computational Models and Applications” in IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP) 2016.
Cost Aggregation and Occlusion Handling with WLS in Stereo Matching, IEEE Trans. on Image Processing (TIP), Aug. 2008
Joint Histogram Based Cost Aggregation for Stereo Matching, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Oct. 2013
Cross-Scale Cost Aggregation for Stereo Matching, IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), May 2017
PatchMatch Filter: Edge-Aware Filtering Meets Randomized Search for Visual Correspondence, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Sep. 2017
Cross-Scale Cost Aggregation for Stereo Matching, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2014
Stereo confidence estimation
The stereo matching has been one of the fundamental and essential topics in the fields of computer vision. It aims to estimate accurate corresponding points between a pair of two images taken under different viewpoints of the same scene. Though numerous methods have been proposed for this task, it still remains an unsolved problem due to several factors including textureless or repeated pattern regions, and occlusions. To improve the matching accuracy, most approaches involve the post-processing step. A set of unreliable pixels is first extracted using confidence measures, and then interpolated using reliable estimates at neighboring pixels. We have presented a learning framework for estimating the stereo confidence through CNNs.
Feature Augmentation for Learning Confidence Measure in Stereo Matching, IEEE Trans. on Image Processing (TIP), Dec. 2017
Unified Confidence Estimation Networks for Robust Stereo Matching, IEEE Trans. on Image Processing (TIP), Mar. 2019
Learning Adversarial Confidence Measures for Robust Stereo Matching, IEEE Trans. on Intelligent Transportation Systems (TITS) (Under review)
LAF-Net: Locally Adaptive Fusion Networks for Stereo Confidence Estimation, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2019 (Oral presentation, <4% acceptance ratio)
Monocular depth estimation
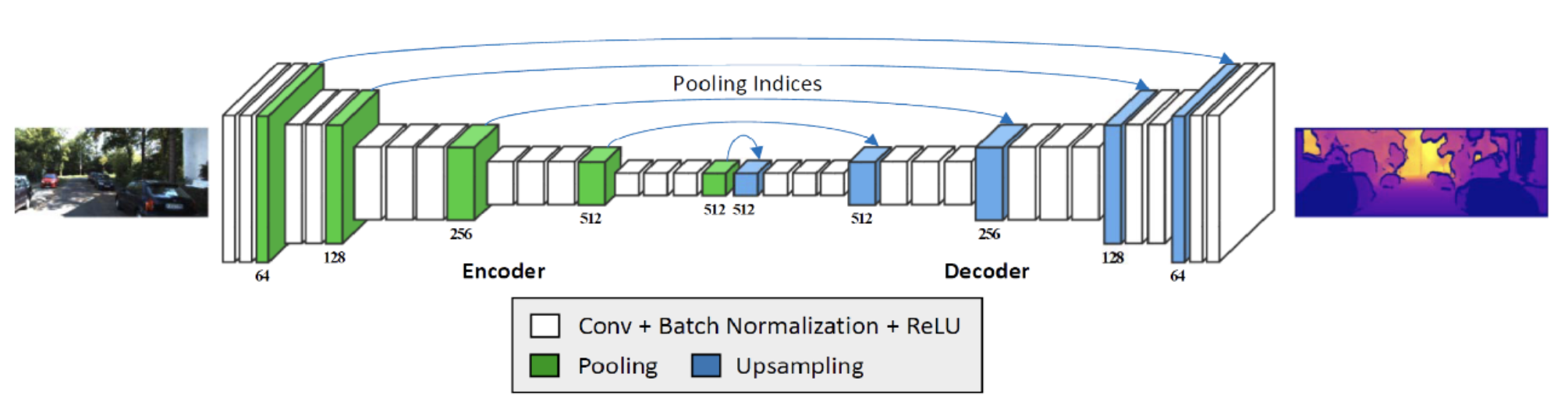
Obtaining 3D depth of a scene is essential to alleviate a number of challenges in robotics and computer vision tasks including 3D reconstruction, autonomous driving, intrinsic image decomposition, and scene understanding. The human visual system (HVS) can understand 3D structure by perceiving a depth value of the scene through binocular fusion. 3D structure is perceived using a binocular disparity that is inferred from slightly different images of the same scene. Such a mechanism has widely been adopted in the computational stereo approaches that establish correspondence maps across two (or more) images taken for the same scene. Interestingly, even with a single image, the HVS is capable of interpreting 3D structure thanks to a prior knowledge learned from monocular cues such as shading, motion, texture, and relative size of objects. In this work, we have developed novel approaches for depth prediction from a single image by making use of convolutional neural networks (CNNs).
Depth Analogy: Data-driven Approach for Single Image Depth Estimation using Gradient Samples, IEEE Trans. on Image Processing (TIP), Dec. 2015
Deep Monocular Depth Estimation via Integration of Global and Local Predictions, IEEE Trans. on Image Processing (TIP), Aug. 2018
A Large RGB-D Dataset for Semi-supervised Monocular Depth Estimation, IEEE Trans. on Intelligent Transportation Systems (TITS) (Under review)
Semantic correspondence
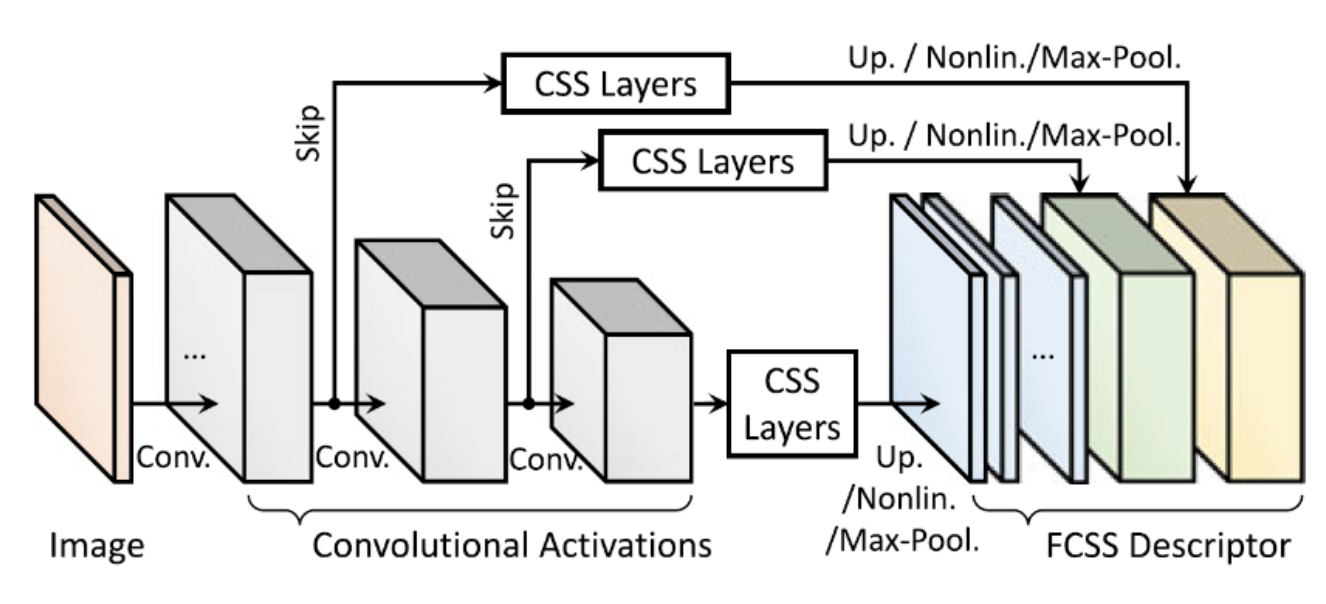
Numerous computer vision and computational photography applications require the points on an object in one image to be matched with their corresponding object points in another image, such as a motorbike wheel matched to a different model of motorbike’s wheel. Dealing with such appearance variations over object instances is essential for numerous tasks such as scene recognition, image registration, semantic segmentation, and image editing. Unlike traditional dense correspondence approaches for estimating depth or optical flow, in which visually similar images of the same scene are used as inputs, establishing dense correspondences across semantically similar images poses additional challenges due to intra-class appearance variations among object instances. We have developed novel CNN-based semantic matching approaches that are insensitive to both intra-class appearance and shape variations while maintaining precise spatial localization ability.
FCSS: Fully Convolutional Self-Similarity for Dense Semantic Correspondence, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Mar. 2019.
Discrete-Continuous Transformation Matching for Dense Semantic Correspondence, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Jan. 2020.
Dense Semantic Correspondence Estimation with Pyramidal Affine Regression Networks, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI) (Under review)
FCSS: Fully Convolutional Self-Similarity for Dense Semantic Correspondence, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jul. 2017
PARN: Pyramidal Affine Regression Networks for Dense Semantic Correspondence Estimation, European Conference on Computer Vision (ECCV), Sep. 2018
Recurrent Transformer Networks for Semantic Correspondence, Neural Information Processing Systems (NIPS), Dec. 2018 (Spotlight, < 4:0% acceptance ratio)
Semantic Attribute Matching Networks, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2019
Joint Learning of Semantic Alignment and Object Landmark Detection, IEEE Int. Conf. on Computer Vision (ICCV), Oct. 2019.
Low-light image restoration
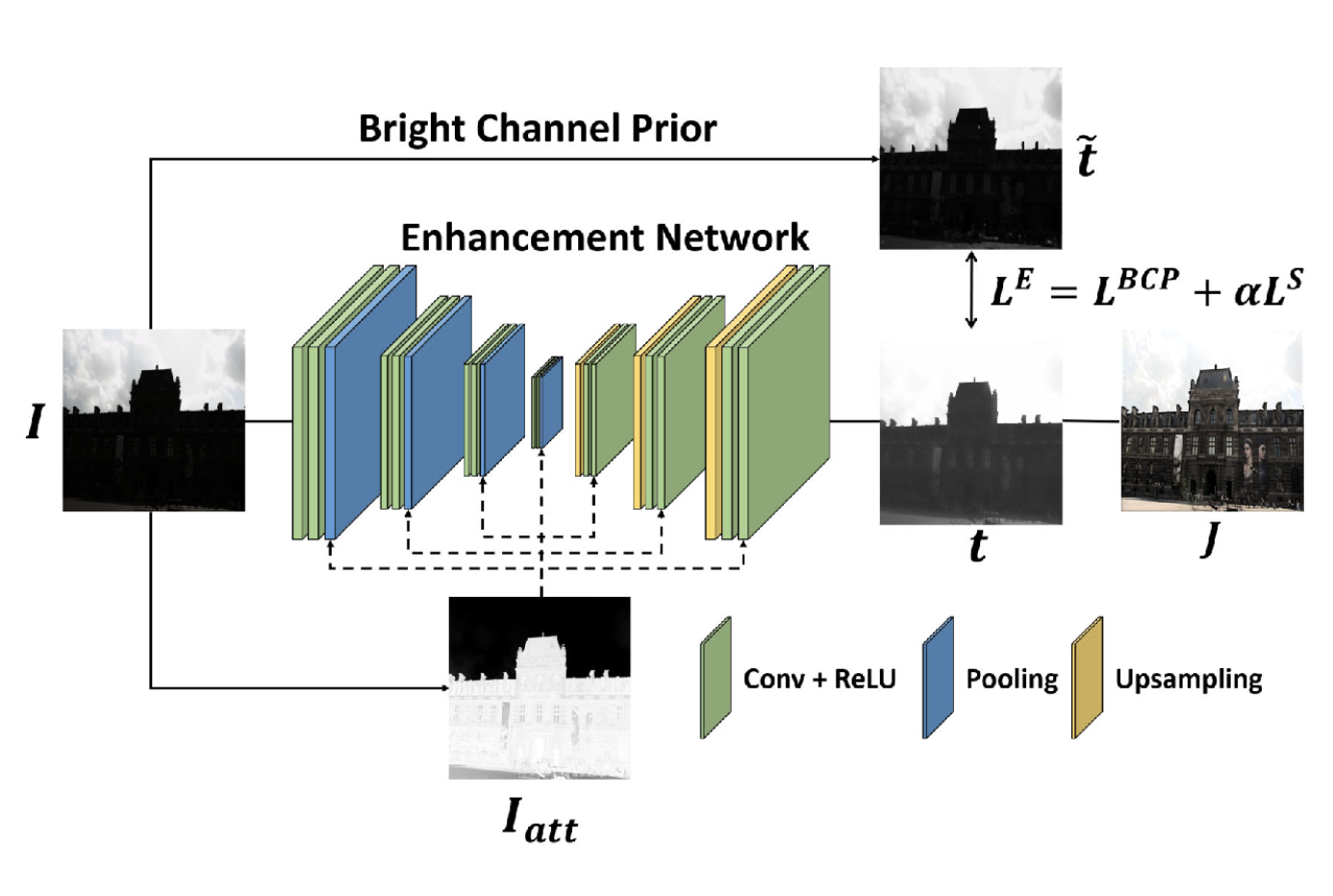
Images acquired in the low-light environment are often degraded by poor visibility and low contrast. High-quality images can be obtained by increasing an exposure time, but this may incur blurs when a scene is not static. Over the past decades, various methods have been proposed to address this degradation. In this work, we propose a novel unsupervised learning approach for the low-light image enhancement.
Unsupervised Low-light Image Enhancement Using Bright Channel Prior, IEEE Signal Processing Letters (SPL), 2020 (Accepted)
Edge-preserving Filtering as Generic Computing Tool for Computer Vision
Nonlinear signal/image filtering is an important and fundamental component for numerous computer vision and graphics applications, which often require decomposing an image into a piecewise smooth base layer and a detail layer. The base layer captures the main structural information, while the detail layer contains the residual smaller scale details in the image. These layered signals can be manipulated and/or recombined in various ways to match different application goals. Over the last few decades, several edge-preserving filtering techniques have been proposed, stemming from different theories and principles. Thanks to their success in achieving high-quality smoothing results and significant computational advantages, these methods have found a great variety of applications. I have also contributed in this domain by developing several filtering algorithms and their applications. Especially, the fast global smoothing (FGS) algorithm was adopted in the official release of OpenCV 3.1 as of Dec. 2015.
Robust Scale Space Filter with Second Order Partial Differential Equations, IEEE Trans. on Image Processing (TIP), Sep. 2012
Revisiting the Relationship Between Adaptive Smoothing and Anisotropic Diffusion with Modified Filters, IEEE Trans. on Image Processing (TIP), Mar. 2013
A Generalized Random Walk with Restart and Its Application in Depth Up-sampling and Interactive Segmentation, IEEE Trans. on Image Processing (TIP), Jul. 2013
Fast Global Image Smoothing Based on Weighted Least Squares, IEEE Trans. on Image Processing (TIP), Dec. 2014(This work was included in the official release of OpenCV 3.1 as of Dec. 2015.)
Fast Domain Decomposition for Global Image Smoothing, IEEE Trans. on Image Processing (TIP), Aug. 2017
Learning Deeply Aggregated Alternating Minimization for General Inverse Problems, IEEE Trans. on Image Processing (TIP) (Under review)
Cross-Based Local Multipoint Filtering, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2012
Deeply Aggregated Alternating Minimization for Image Restoration, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jul. 2017 (Spotlight presentation, < 8:0% acceptance ratio)
Depth map processing
Dense depth often serves as a fundamental building block for many computer vision and computational photography applications, e.g., 3D scene reconstruction, object tracking, video editing, to name a few. An active range sensing technology such as time-of-
ight (ToF) cameras has been recently advanced, emerging as an alternative to obtaining a depth map. It provides 2D depth maps at a video rate, but the quality of ToF depth maps is not as good as that of a high-quality color camera. The depth map is of low-resolution and noisy, and thus a post-processing for depth upsampling is usually required to enhance the quality of depth maps. We have developed novel approaches for enhancing or interpolating the depth map.
Depth Video Enhancement Based on Weighted Mode Filtering, IEEE Trans. on Image Processing (TIP), Mar. 2012
Depth Super-Resolution by Transduction, IEEE Trans. on Image Processing (TIP), May 2015
Efficient Techniques for Depth Video Compression Using Weighted Mode Filtering, IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), Feb. 2013
Fast Guided Global Interpolation for Depth and Motion, European Conference on Computer Vision (ECCV), Oct. 2016
Feature Matching Descriptors
Local image descriptors have long been studied in the computer vision literature due to its numerous applications. Examples include Scale Invariant Feature Transforms (SIFT) [20], Speeded-Up Robust Features (SURF) [21], to name a few. These descriptors typically produce high-dimensional feature descriptors for sparse salient points only, and are generally known to be robust against geometric variations (e.g. scale and rotation). While they have been used for sparse matching, recent works attempt to employ the local image descriptors with global discrete labeling methods together for computing dense correspondences. The performance of these descriptors, however, would be severely degenerated when input images are substantially different due to illumination, low-lighting conditions, or different spectral sensitivities. Such real-world challenges are common for unstrained image pairs that are typically used in image processing applications. We have developed local image descriptors to overcome several challenges that often appear under non-ideal image scenarios.
DASC: Robust Dense Descriptor for Multi-modal and Multi-spectral Correspondence Estimation, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Sep. 2017
Dense Cross-Modal Correspondence Estimation with the Deep Self-Correlation Descriptor, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020 (Accepted)
DASC: Dense Adaptive Self-Correlation Descriptor for Multi-modal and Multi-spectral Correspondence, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2015
Deep Self-Correlation Descriptor for Dense Cross-Modal Correspondence, European Conference on Computer Vision (ECCV), Oct. 2016
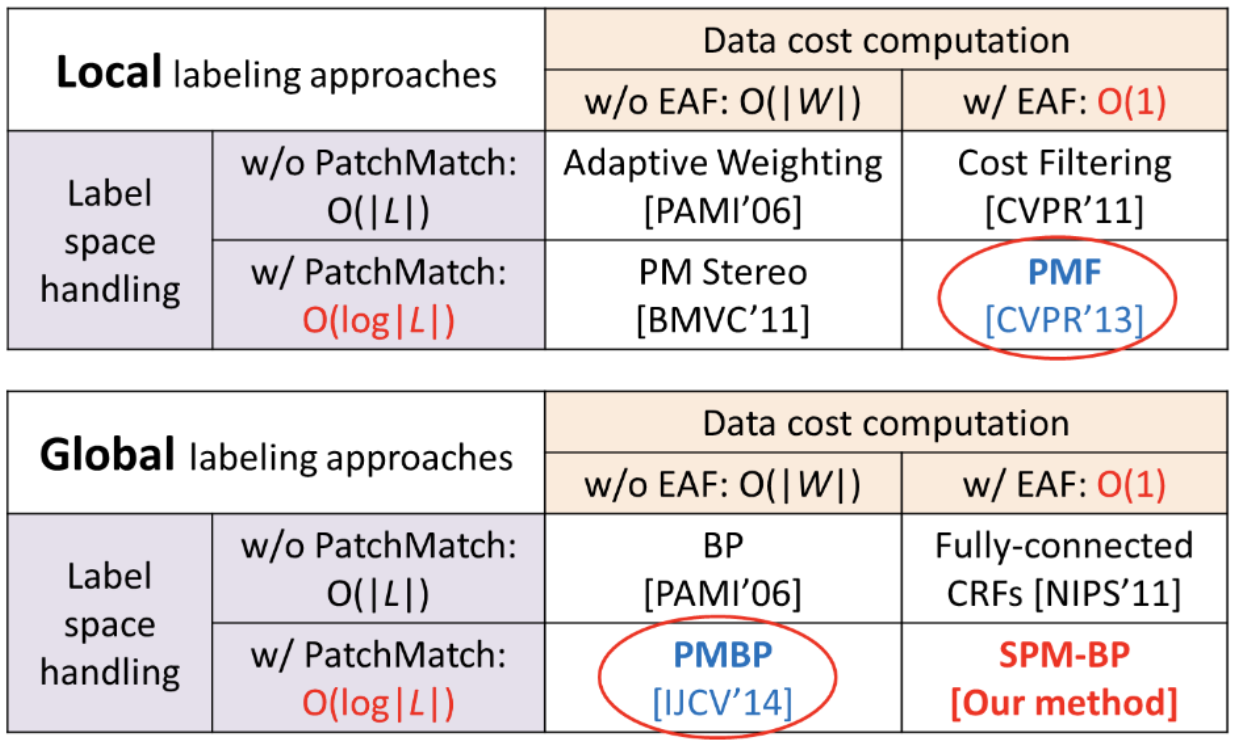
Fast Labeling Optimization
Probabilistic graphical models are proven to be effective in many discrete labeling tasks, where the labels range from low-level measurements such as motion and depth to high-level semantic labels such as object class, region of interest, and sentiments. Most existing approaches model the labeling problem based on the Markov Random Fields (MRF) or the Conditional Random Fields (CRF) by considering a pair-wise interaction of the neighboring labels, and then optimize the model using the graph cut or the message passing algorithms. Recent studies showed that such a pair-wise interaction is insufficient to propagate labels reliably over large regions. By revisiting the mean-field approximation theory, which has been widely used in the optimization community, they proposed a new method for efficient inference on the fully connected MRF or CRF models, enabling more efficient, high-order interaction. This method significantly accelerates the speed and quality of the message passing mechanism with the help of efficient edge-aware filtering approaches. Despite its excellent performance in achieving high-quality solution for the CRF model with the fully connected interaction, this inference machine does not fit well to a large-scale visual data scenario. Since its computational complexity still depends on the size of the label space to be searched, which is usually very large, the inference algorithm often becomes computationally intractable in case of dealing with the large-scale visual data. We have been working on this issue by developing advanced labeling optimization algorithms.
Joint Histogram Based Cost Aggregation for Stereo Matching, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Oct. 2013
PatchMatch Filter: Edge-Aware Filtering Meets Randomized Search for Visual Correspondence, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Sep. 2017
Discrete-Continuous Transformation Matching for Dense Semantic Correspondence, IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Jan. 2020.
A Revisit to Cost Aggregation in Stereo Matching: How Far Can We Reduce Its Computational Redundancy?, IEEE Int. Conf. on Computer Vision (ICCV), Nov. 2011 (Oral presentation, < 4:0% acceptance ratio)
PatchMatch Filter: Efficient Edge-Aware Filtering Meets Randomized Search for Fast Correspondence Field Estimation, IEEE Int. Conf. on Computer Vision and Pattern Recognition (CVPR), Jun. 2013 (Oral presentation, < 4% acceptance ratio)
In contrast to the conventional TV, three-dimensional (3D) TV aims to provide a user with an immersive 3D perception and interactivity. The viewer can perceive 3D impression throughout a 3D display with or without wearing glasses, and change the viewpoint according to an individual preference. By passing through the development phase, 3D TV has been successfully deployed on commercial markets, and is spotlighted as the core equipment of the next generation broadcasting system. one of the most important technologies is to synthesize intermediate views with two or more images captured at different viewpoints. In this work, we developed a novel method that effectively handles rendering artifacts from erroneous depth data by formulating the rendering process
Probability-Based Rendering for View Synthesis, IEEE Trans. on Image Processing (TIP), Feb. 2014